
Say Hi to faster processing with Pandas
Unlock faster processing in Pandas.
Context
- The main focuses of this blog is to promote using storage optimised data frames and moving away from the traditional for loops to apply, lambda functions and vectorization techniques.
- The blog is in two parts
- Part 01: Optimising the data frame.
- Part 02: Moving away from for loops to Map/Apply functions and using Vectorization.
Importing Necessary Libraries
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
Data
- Synthetic data is created with a mix of numerical and categorical features.
- 100k rows are generated using random functions.
- Height, Weight, and Age are the numerical features with both of integers and floats.
- BMI, Diabetes, and Blood Pressure are categorical features.
Generating Synthetic Data
df = pd.DataFrame()
np.random.seed(111)
df['Height'] = np.random.normal(5,1,100000)
df['Weight'] = np.random.random_integers(40,120,100000)
df['Age'] = np.random.random_integers(0,100,100000)
df['BMI'] = np.random.choice(['Under weight','Normal','Slightly Obese','Obese'],100000)
df['Diabetes'] = np.random.choice(['Yes','No'],100000)
df['BP']= np.random.choice(['Yes','No'],100000)
Preview the data
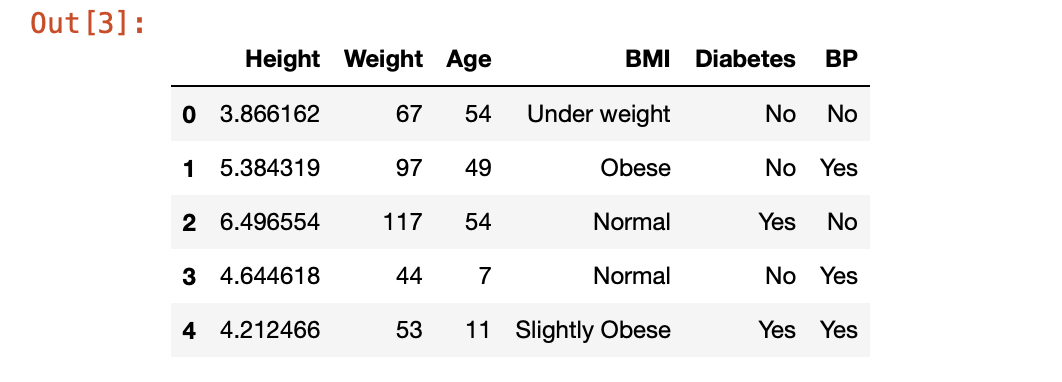
Part 01 - Optimising the data frame size
Challenge
- In my past works, I used to put less emphasis on using the optimised or storage efficient data frames.
- Eventually as my data grew, It started to bite my coding time, became less efficient and time consuming to do even the smaller tasks.
- This might not be obvious when it comes to handling smaller data frames. However, dealing with larger data frames could be highly challenging if they are not optimised for space.
Solution
- The following part will show you a sneak peak of how small changes to the data frame could reduce your size by great extent.
- Hence resulting in faster performance and efficient data wrangling.
Data Frame Info
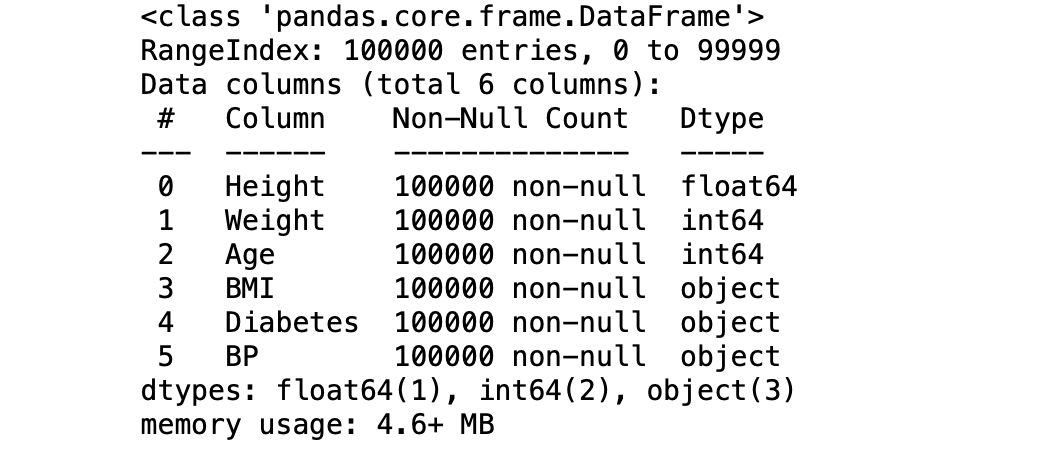
Findings
- The above data frame takes up 4.6 MB of memory.
- Numerical features Weight and Age are of type ‘int64’. Realistically the weight and age could not exceed above 300 kgs and 120 years respectively. This assumption is maximum possible value.
- Height, The tallest person ever could be probably 10 feet.
- Pandas by default assigns int64 type to these variables. int64 take the possible range of -2,147,483,648 to 2,147,483,647 such range is unlikely for these features.
- Weight could be set as int16 type which takes the range of -32,768 to 32,767.
- Age could be set as int8 which takes the range of -127 to 127.
- Height could be scaled down to the type float32.
Casting Numerical types
#Converting the types
df['Age'] = df['Age'].astype('int8')
df['Weight'] = df['Weight'].astype('int16')
df['Height'] = df['Height'].astype('float32')
df.info()
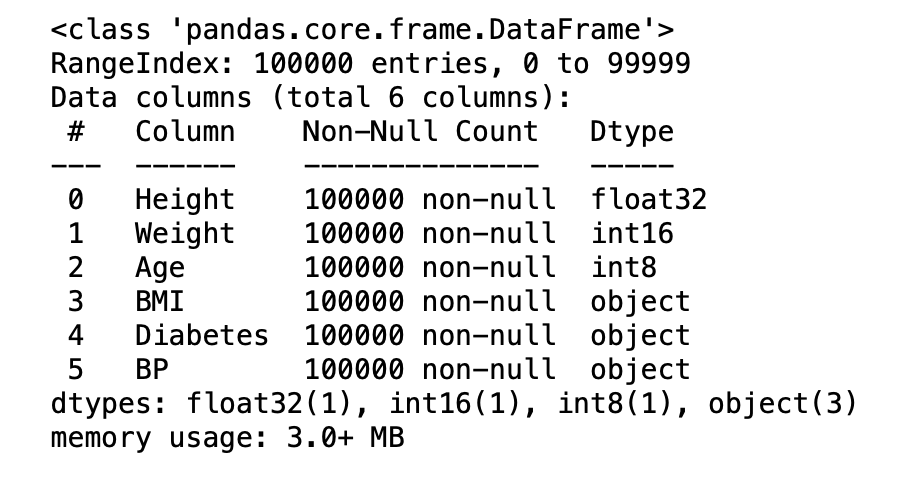
Results
- The data frame is down to 3 MB, That’s a reduction by ~35%.
- The Categorical variables BMI, Diabetes, BP do not have cardinality >5. by default, they are assigned object type. But using Category is the more suitable dtype.
Casting Categorical Type
#Converting the types
df['BMI'] = df['BMI'].astype('category')
df['BP'] = df['BP'].astype('category')
df['Diabetes'] = df['Diabetes'].astype('category')
df.info()
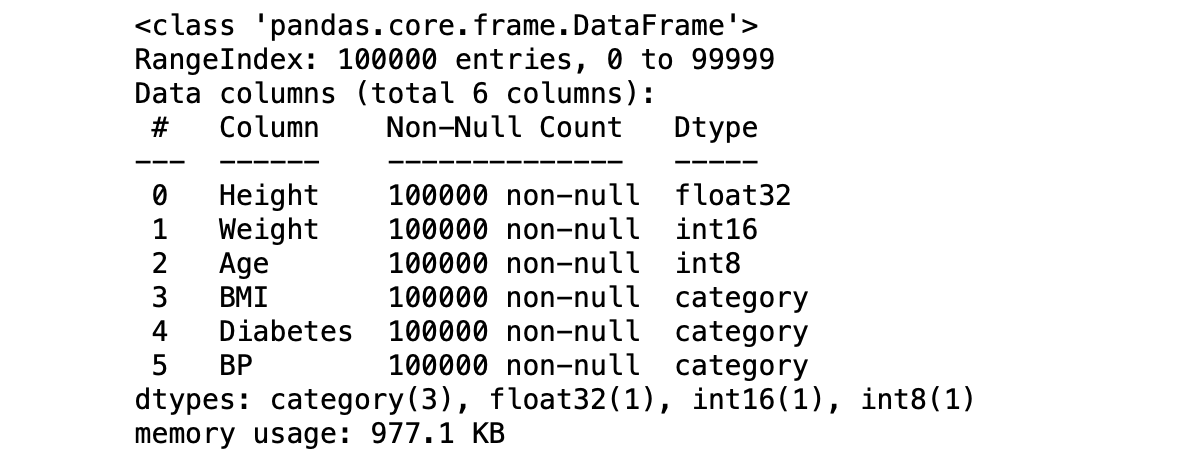
Results
- The data frame is down to 977.1 KB. A reduction by ~80% of original size.
- This data frame is now much efficient, optimised for space and will increase the code performance drastically.
Part 02: Moving away from For loops
Background
- To do any operations on lists/series/dataframes, The first thing that comes to my mind is using for loops.
- Which has been the traditional approach to handle these situations. However there are certain caveats with for loops:
- High code compile time.
- Large lines of code.
- Inefficient when it comes to larger data frames.
Solution
- The transition from for loops do certainely have bigger benefits such as low code compile time, faster processing, and less lines of code.
- Using apply functions and vectorization could achieve this milestone. The process is demonstrated by converting the Height in feet to metres using the for loop, apply function and Vectorization technique.
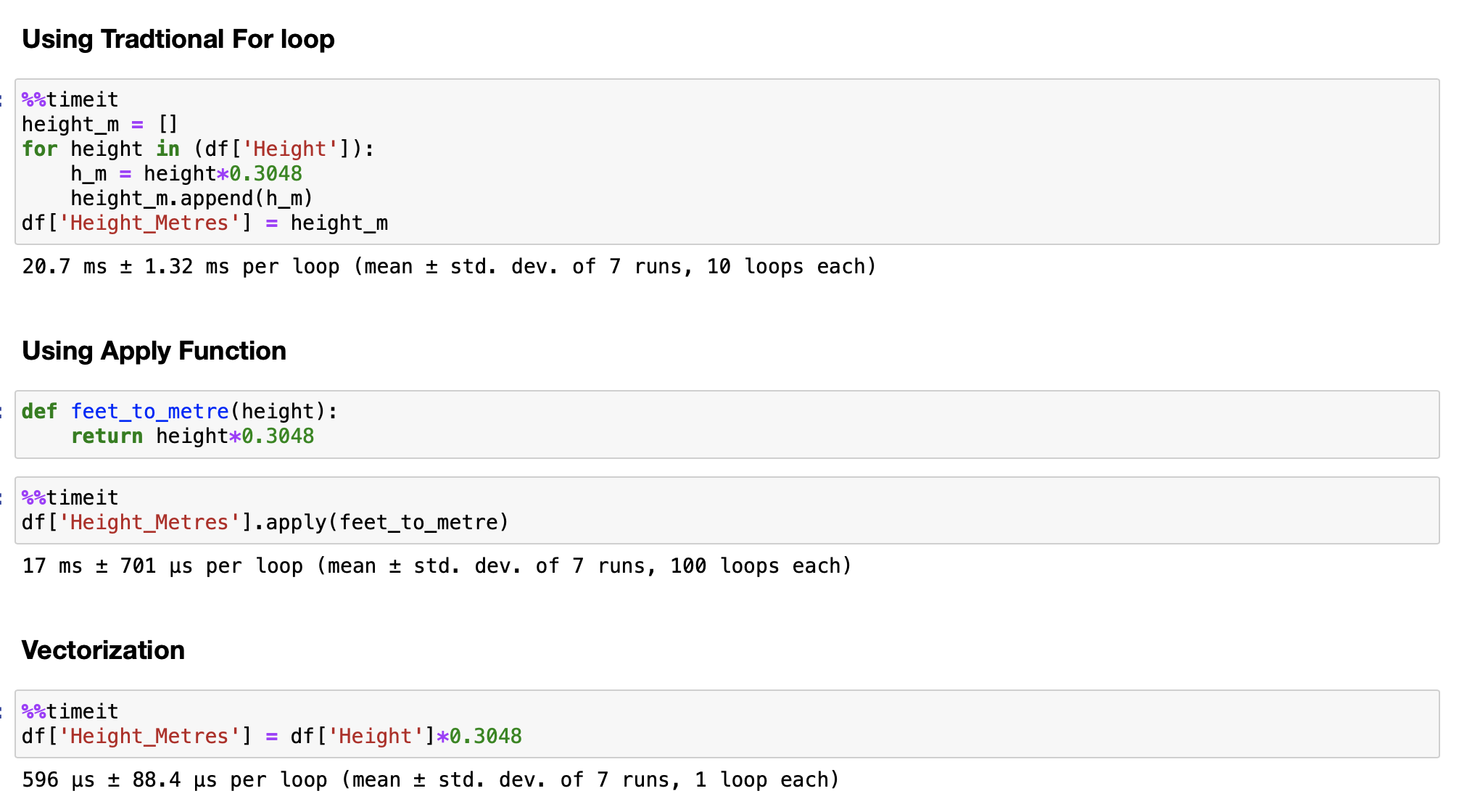 Results
Results
- The Above is the simple illustration of how faster the Apply and Vectorization could be.
- The traditional for loop took 20.7 milli seconds to convert the height feature in feet to metres.
- Whereas the Apply function gave a very good improvement by reducing the time to 17 milli seconds.
- The vectorization is the game changer, It took just 596 micro seconds(0.596 milli seconds) to run the process.
- The benefits of moving away from for loops even in simpler tasks are very obvious.
- Hence it is highly recomended to use apply/lambda functions, and Vectorization techniques when handling larger data sets for faster processing.